What is Nextmv?
Nextmv is a decision automation platform. We offer developer tools to build custom decision models, a modern cloud-based architecture to manage, optimize, and improve these models, and a web app to collaborate with others while doing so.
We wanted a platform that felt like other modern tools that we could use to take decision models from local development to remote deployment with confidence. We couldn’t find them so we built them. This is the Nextmv Platform.
Core features
- Developer tools. Build and run custom models on your local machine with our command line interface (CLI) and Python SDK. You can build from scratch or start from one of our community apps, and integrate with other solvers.
- Modern workflows. Our platform is cloud-native and built to deploy your custom decision models to remote environments with the least amount of friction.
- Custom decision apps. A custom model when deployed remotely is housed in an app. A custom app contains all of the iterations of your decision model managed with versions and instances, and a record of runs and experiments made. Each app comes with a set of unique API endpoints to run and manage it.
- Pre-built decision apps. We also offer pre-built, domain-specific decision apps that are production-ready out of the box. These pre-built apps are managed and deployed using the same infrastructure as custom decision apps.
- Frameworks to experiment. We have a suite of experiment tools — including scenario, batch, acceptance, shadow, and switchback tests — to help you manage model changes and enhancements without surprises or disruption to your business.
- Ensembles and secrets. Group multiple instances into ensembles for advanced routing and comparison. Manage sensitive configuration with secrets collections.
- Integrations and webhooks. Connect your decision apps to external services like Databricks and AWS Batch. Set up webhooks to trigger actions on platform events.
- Web app for collaboration & access. Nextmv Console is a web app that can be used to manage your apps and run experiments without having to be a developer. You can invite multiple members to your team to enable collaboration and cross-team access to your decision apps.
The core concept pages for each of these will give you foundational understanding of how the Nextmv Platform operates. Then dive into the domain-specific sections and references for detailed tutorials and guides on how to make the most of the Nextmv Platform.
Decision services
We think about decisions as code, meaning we use our platform to create decision services. But what is a decision service? It looks a little something like this.
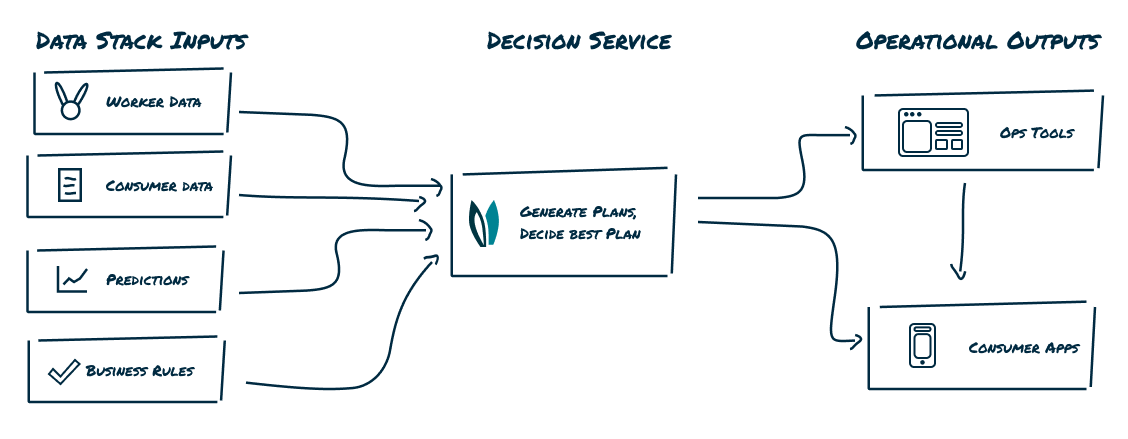
Decision services sit between the data stack and the operation and operate at scale to provide ops with the best plan in the time they have to run.
These services take in structured operational data (we prefer JSON), generate possible plans that assign and sequence tasks, compare those plans based on a value function that is important to the business (KPI = on time deliveries), and return the best one.
This plan is then sent as structured output downstream to operations tooling (who doesn’t love a good dashboard) or consumer applications (they show us ads, promos, ETAs, or prices). A plan is a snapshot in time of what the decision service thinks the operation should take action on based on current information.
Things change. That’s why we have a decision service! We can re-plan as often as we want, triggered on new events or scheduled cadences.