⌛️ Approximate time to complete: 20 min.
In this tutorial you will learn how to bring your own decision model to the Nextmv Platform, from scratch. Complete this tutorial if you:
- Have a pre-existing decision model and you want to explore the Nextmv Platform using the Python SDK.
- Are fluent using Python 🐍.
To complete this tutorial, we will use two external examples, working under the principle that they are not Nextmv-created decision models. You can, and should, use your own decision model, or follow along with the examples provided:
At a high level, this tutorial will go through the following steps using both examples:
- Nextmv-ify the decision model.
- Run it locally.
- Track local runs remotely.
- Push the model to Nextmv Cloud.
- Run the model remotely.
- Perform scenario testing.
Let’s dive right in 🤿.
1. Prepare the executable code
If you are working with your own decision model and already know that it executes, feel free to skip this step.
The decision model is composed of executable code that solves an optimization problem. Copy the desired example code to a script named main.py.
2. Install requirements
If you are working with your own decision model and already have all requirements ready for it, feel free to skip this step.
Make sure you have the appropriate requirements installed for your model. If you don't have one already, create a requirements.txt file in the root of your project with the Python package requirements needed.
Install the requirements by running the following command:
The Pyomo example uses the GLPK solver. Make sure you install it as well.
For Windows, install from SourceForge.
3. Run the executable code
If you are working with your own decision model and already know that it executes, feel free to skip this step.
Make sure your decision model works by running the executable code.
Here is the output produced by both examples.
4. Nextmv-ify the decision model
We are going to turn the executable decision model into a Nextmv application.
So, what is a Nextmv application? A Nextmv application is an entity that contains a decision model as executable code. An application can make a run by taking an input, executing the decision model, and producing an output. An application is defined by its code, and a configuration file named app.yaml, known as the "app manifest".
Think of the app as a shell, or workspace, that contains your decision model code, and provides the necessary structure to run it.
A run on a Nextmv application follows this convention:
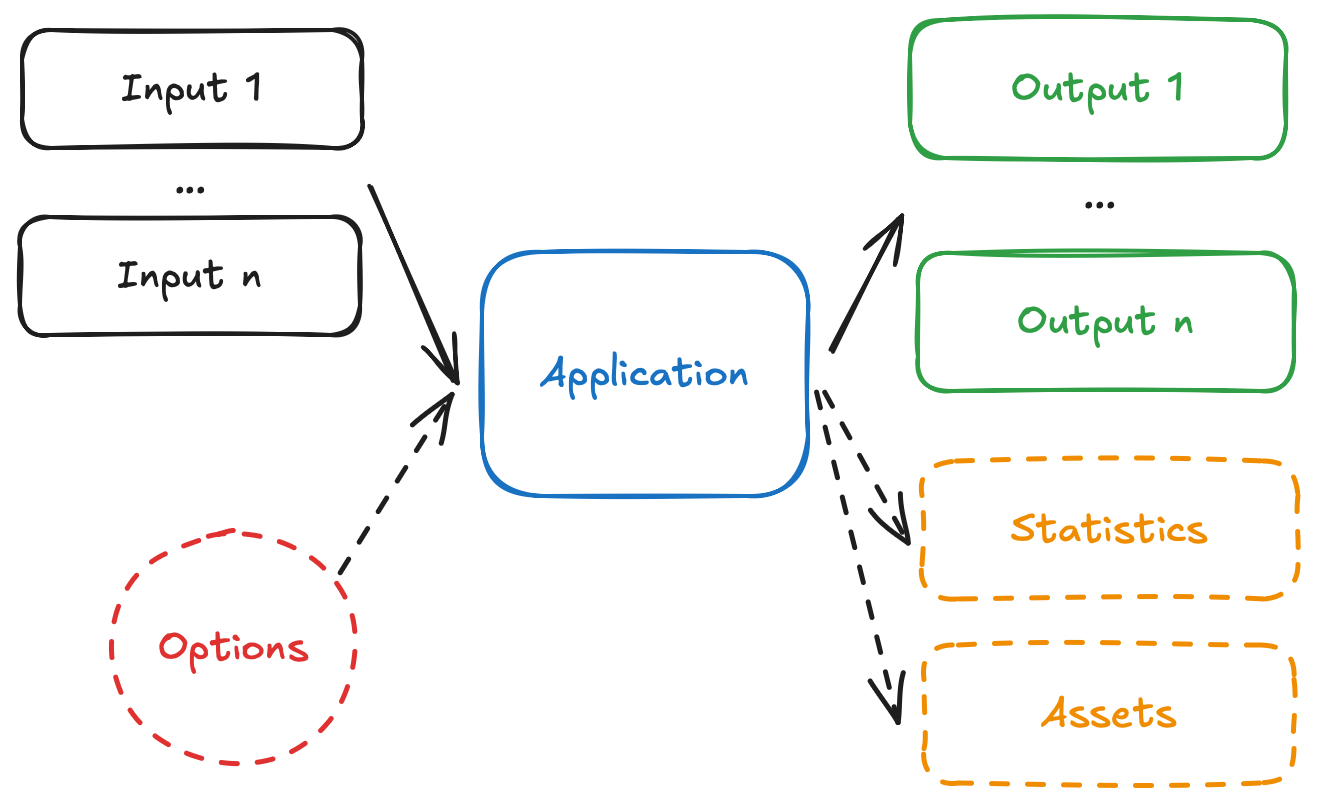
- The app receives one, or more, inputs (problem data) through
stdinor files. - The app run can be configured through options that are received as CLI arguments.
- The app processes the inputs, and executes the decision model.
- The app produces one, or more, outputs (solutions) and prints to
stdoutor files. - The app optionally produces statistics (metrics) and assets (can be visual, like charts).
We are going to adapt the examples so that they can follow these conventions.
Start by adding the app.yaml file, which is known as the app manifest, to the root of the project. This file contains the configuration of the app.
This tutorial is not meant to discuss the app manifest in-depth, for that you can go to the manifest docs. However, these are the main attributes shown in the manifests:
type: both arepythonapplications.runtime: Pyomo uses the specialpyomo:latestruntime, as it comes with solvers pre-installed. HiGHS uses the standardpython:3.11runtime.files: contains files that make up the executable code of the app. In both cases only a singlemain.pyfile is needed. Make sure to include all files and dirs that are needed for your decision model.python.pip-requirements: specifies in both cases the file with the Python packages that need to be installed for the application.configuration.content: Pyomo will use thejsonformat, so it does not need additional configurations. HiGHS will usemulti-file, so additional configurations are needed. As you complete this tutorial, the difference between the two formats will become clearer.configuration.options: for both examples, we are adding options to the application, which allow you to configure runs, with parameters such as solver duration.
For both examples, a dependency for nextmv (the Nextmv Python SDK) is also added. This dependency is optional, and SDK modeling constructs are not needed to run a Nextmv Application. However, using the SDK modeling features makes it easier to work with Nextmv apps, as a lot of convenient functionality is already baked in, like:
- Reading and interpreting the manifest.
- Easily reading and writing files based on the content format.
- Parsing and using options from the command line, or environment variables.
- Structuring inputs and outputs.
These are the new requirements.txt
Now, you can overwrite your main.py files with the Nextmv-ified version.
This is a short summary of the changes introduced for each of the examples:
- Pyomo
- Load the app manifest from the
app.yamlfile. - Extract options (configurations) from the manifest.
- The input data is no longer in the Python file itself. We will move it to a file under
inputs/problem.json. In a singlejsonfile we will define the complete input. Given that we are working with thejsoncontent format, we use the Python SDK to load the input data fromstdin. - Modify the definition of sets, and parameters to use the data from the loaded input.
- Store the solution to the problem, and solver metrics (statistics), in an output.
- Write the output to
stdout, given that we are working with thejsoncontent format.
- Load the app manifest from the
- HiGHS
- Load the app manifest from the
app.yamlfile. - Extract options (configurations) from the manifest.
- The input data is no longer in the Python file itself. We are representing the problem with several files under the
inputsdirectory. Ininputs/edges.csvwe are going to write the edges with their corresponding weights. Ininputs/nodes.jsonwe are going to set the information about nodes, like which node is the origin and which is the destination. When working with more than one file, themulti-filecontent format is ideal. We use the Python SDK to load the input data from the various files. - Modify the definition of nodes, edges, and decision variables to use data from the loaded inputs.
- Store the solution to the problem, and solver metrics (statistics), in an output.
- Write the output to several files, under the
outputsdirectory, given that we are working with themulti-filecontent format.
- Load the app manifest from the
Here are the data files that you need to place in an inputs directory.
Pyomo
HiGHS
After you are done Nextmv-ifying, your Nextmv app should have the following structure, for the examples provided.
Now you are ready to explore the Nextmv Platform 🥳.
5. Install the Nextmv Python SDK
Install the Nextmv Python SDK, with additional requirements:
Please note that even if you are not using the Python SDK's modeling constructs as part of your executable code, you still need to install it for this tutorial. On the other hand, if you decided that you want to use the Python SDK for the executable code, you would have needed to install it.
6. Run the Nextmv application locally
The local package of the Nextmv Python SDK provides functionality to run Nextmv applications locally on your machine.
The local experience is completely free of charge and does not require a Nextmv account.
Create a script named app1.py, or use a cell of a Jupyter notebook. Copy and paste the following code into it, making sure you use the correct app src (for this example, the current working directory, ".").:
When you instantiate a local application, the src argument must point to a directory where the app.yaml manifest file is located.
This will print the IDs of the runs created. The app runs start in the background. Run the script, or notebook cell, to get an output similar to this:
The local package allows you to perform runs on the application and store the inputs, options, logs, and outputs that are associated with the run. As you can tell, depending on the content format used for each application, you work with the data differently.
- For a
jsonapplication, you send adictto thenew_runmethod. - For a
multi-fileapplication, you specify a dir where the input files are stored.
Similarly, the content format dictates how to get the output data.
- For a
jsonapplication, the outputdictcan be obtained from the results. - For a
multi-fileapplication, the output files are written to the path specified in the argument.
The run is started and completed in a background process. Instead of sleeping and waiting for the results, you can poll for the run to be finished.
Create another script, which you can name app2.py, or use another cell in the Jupyter notebook. Copy and paste the following code into it, making sure you use the correct app src:
Running the app2.py script (or the new notebook cell), you'll notice that the results are duplicated, as you are performing the same run but waiting for the results concurrently.
If you inspect the file structure of your application, you will find a tree similar to this:
The .nextmv dir is used to store and manage the local applications run in a structured way. The local package is used to interact with these files, with methods for starting runs, retrieving results, visualizing charts, and more.
7. Create an account
The local experience is a great free starting point, but the full suite of benefits starts with a Nextmv Cloud account.
- Visit the Nextmv Console to sign up for an account at https://cloud.nextmv.io.
- Verify your account.
- You’ll receive an email asking to verify your account.
- Follow the link in that email to sign in.
- Log in to your account. The Nextmv Console is ready to use!
Once you have logged in to your account, you need to fetch your API key. You can do so from your settings.

When you have your API key, it is convenient to save it as an environment variable so that you can use it for the rest of this tutorial.
8. Create a Nextmv Cloud application
Create another script, which you can name app3.py, or use another cell in the Jupyter notebook. Copy and paste the following code into it:
After you run the script, or notebook cell, you should see an output similar to this one, where it confirms that the app was created successfully.
You can go to the Apps section in the Nextmv Console where you will see your applications.

9. Sync local runs to Nextmv Cloud
Create another script, which you can name app4.py, or use another cell in the Jupyter notebook. Copy and paste the following code into it, making sure you use the correct app src:
You will now track these runs in Nextmv Cloud, as external runs. After you run the script, or notebook cell, you should see an output similar to this one, where it shows which runs were synced successfully.
Depending on the number of times you run the script, you might be syncing more or fewer runs.
You can go to the apps section in the Nextmv Console where you will see your application. You can click on it to see more details. In the overview of the app you will see the most recent runs. Click on any of the runs that were tracked.
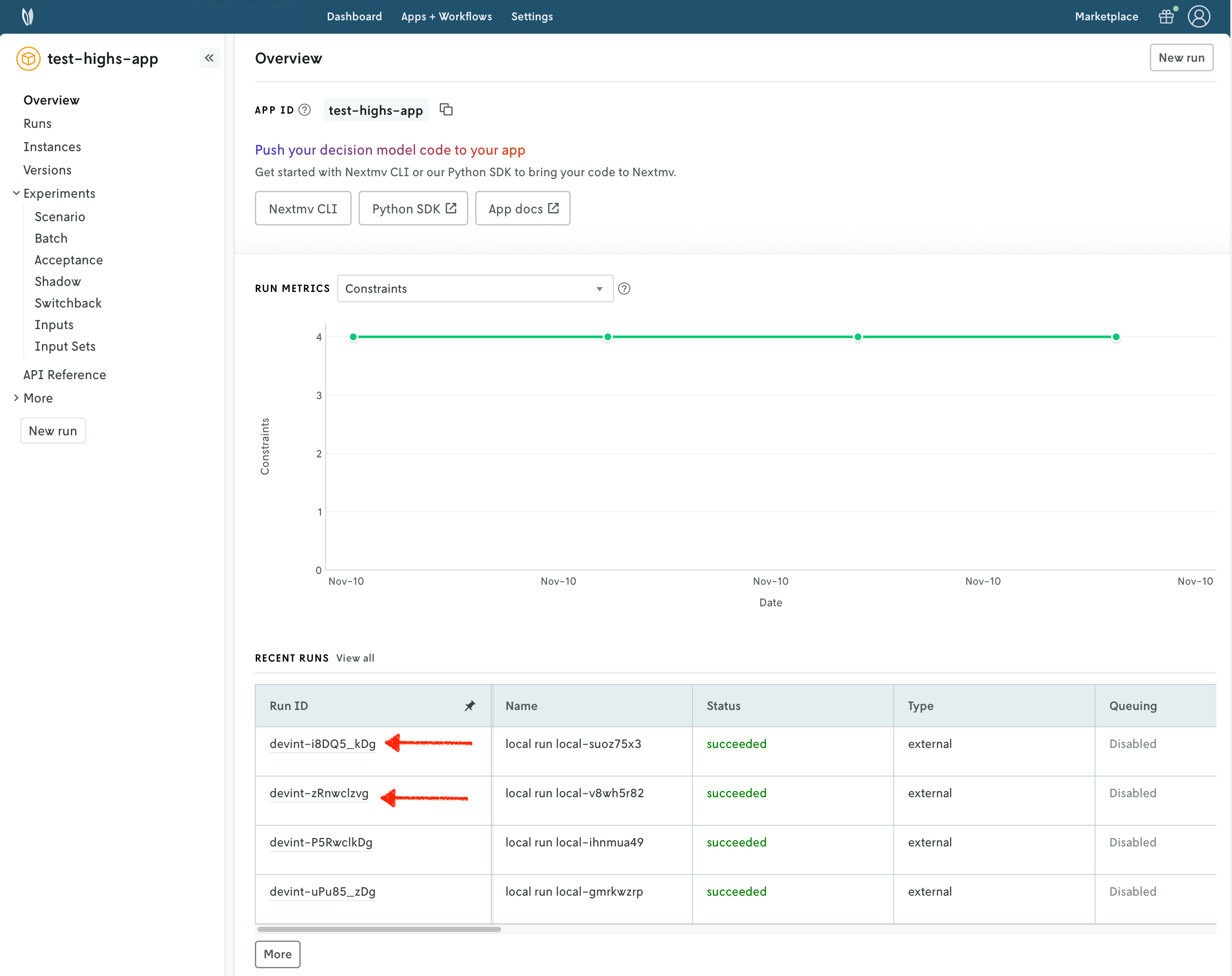
You can use the Nextmv Console to browse the information of the run:
- Summary
- Output
- Input
- Metadata
- Logs
Nextmv is built for collaboration, so you can invite team members to your account and share run URLs.
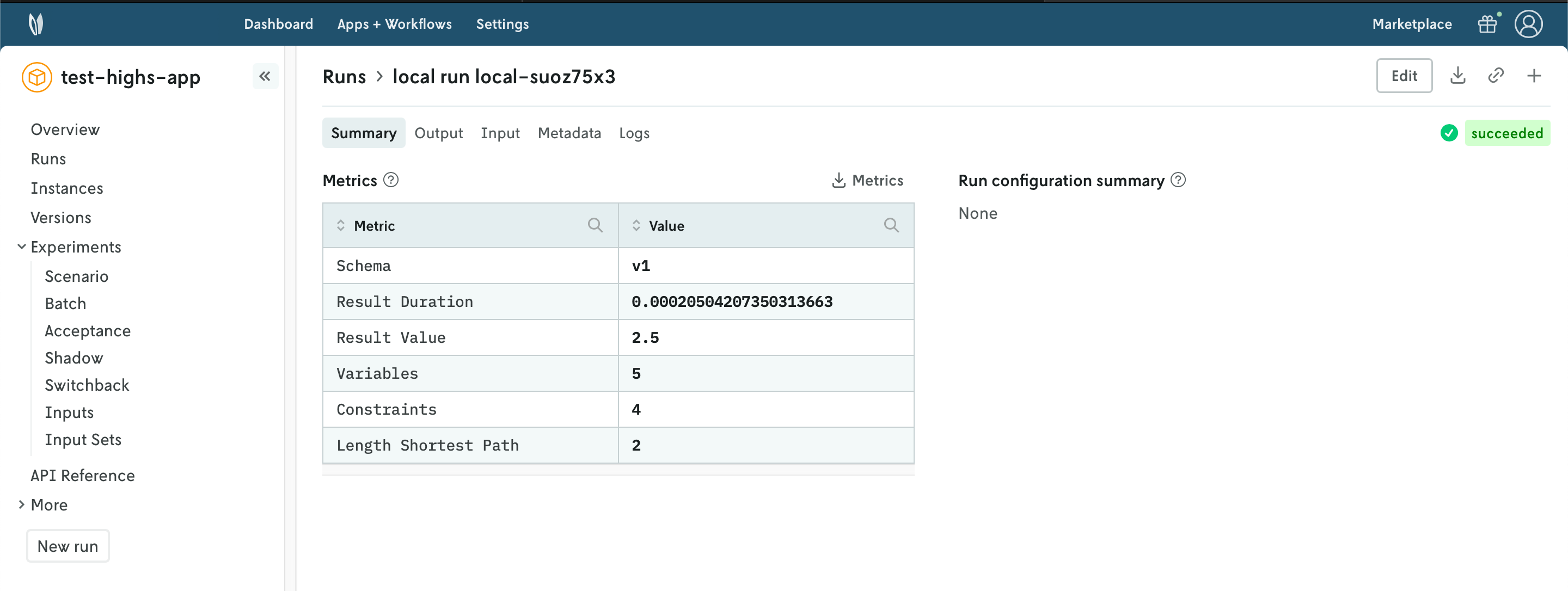
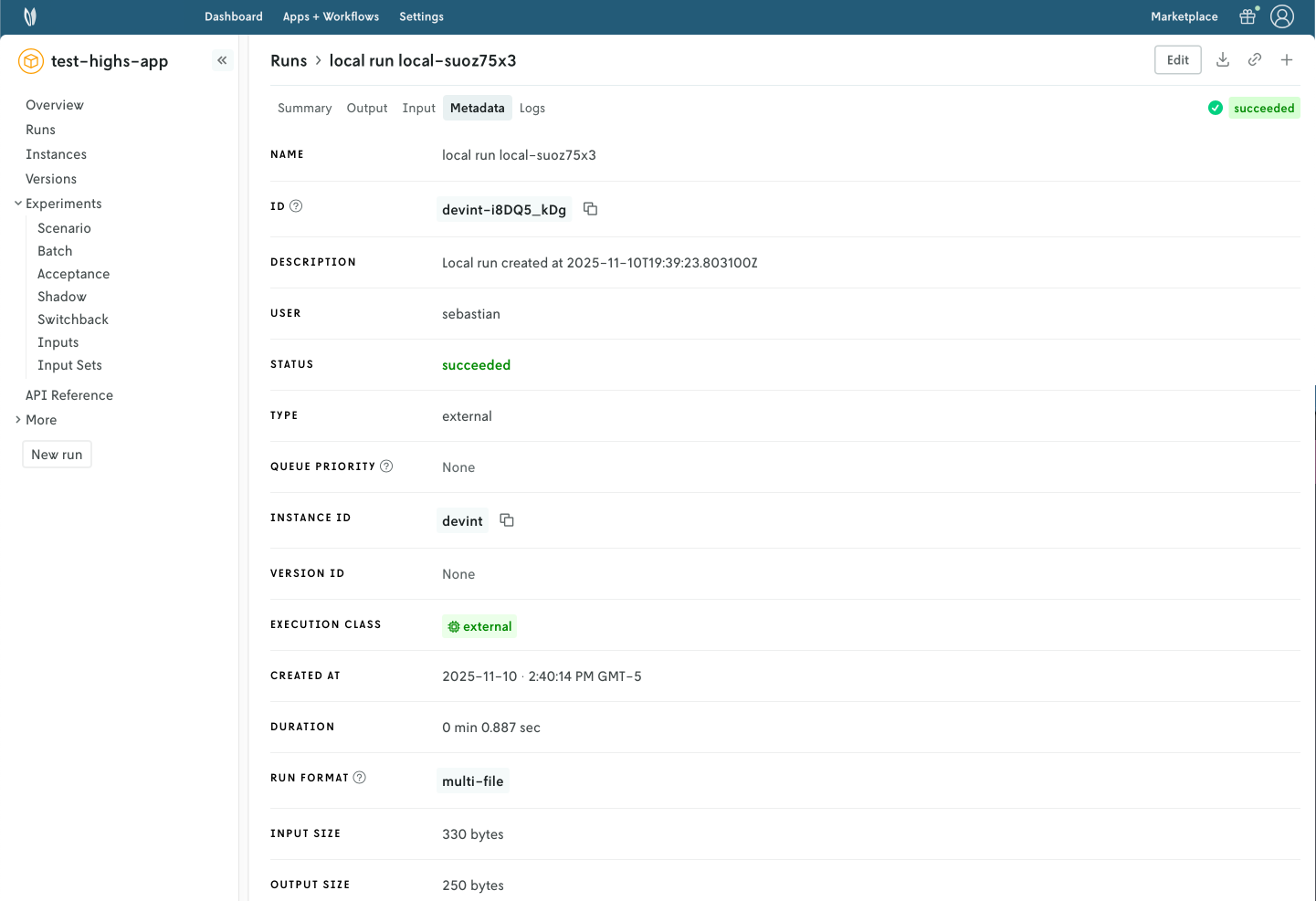
10. Subscribe to a Nextmv Plan
If you already have an active Nextmv Plan, you can skip this step.
If a Nextmv member provides different instructions for activating a Nextmv Plan, please follow those instructions instead.
Upgrade your account and subscribe to a Nextmv Plan. In the Nextmv Console, you can do this from the Upgrade button or from the Settings > Plan section.
Running a custom application remotely in Nextmv Cloud requires a paid plan. However, plans come with a 14-day free trial that can be canceled at any time. You can upgrade your account and subscribe to a plan in Nextmv Console by clicking the Upgrade button in the header, or navigating to the Settings → Plan section. Upgrading to a plan will allow you to complete the rest of the tutorial.
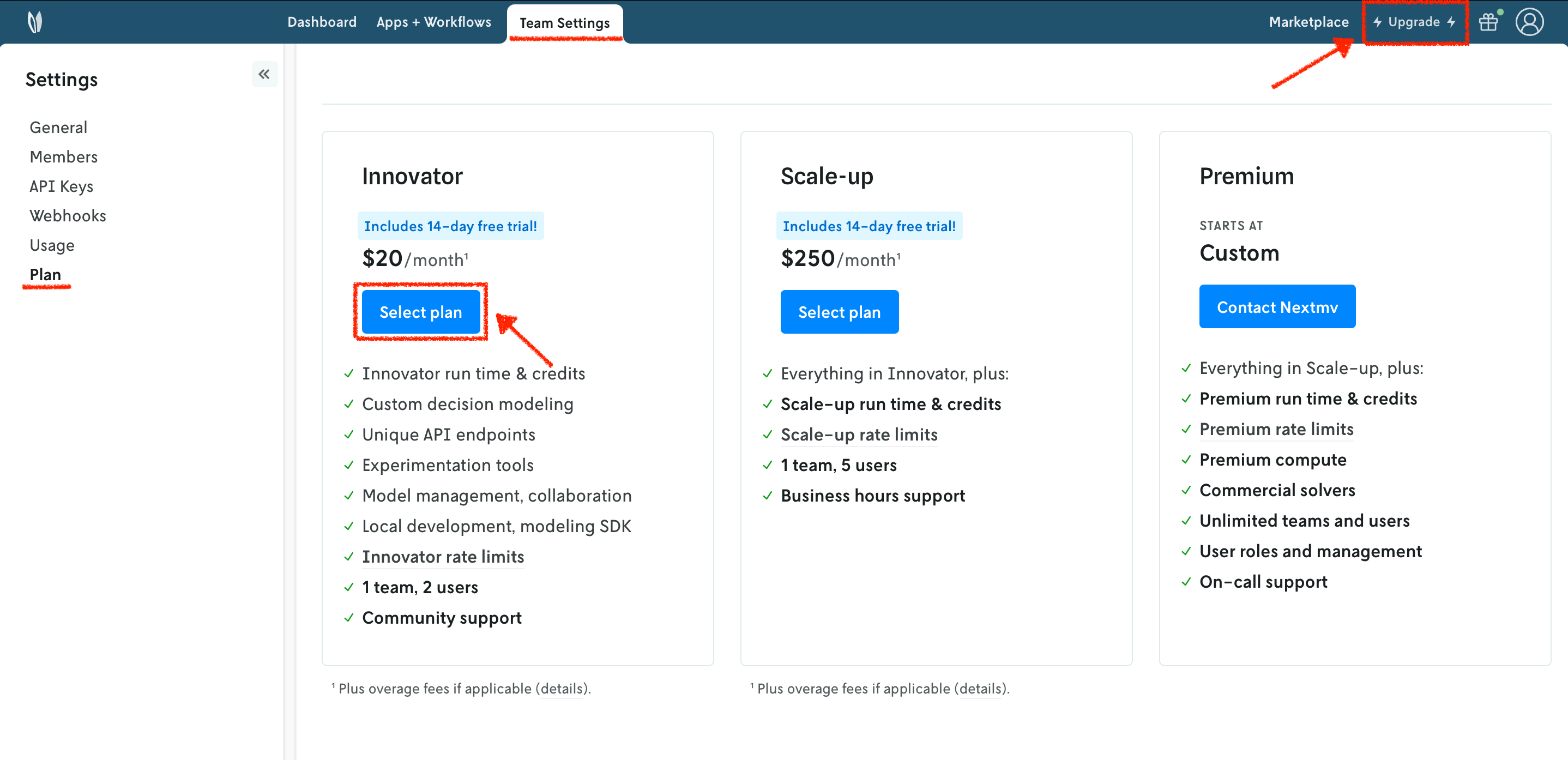
In the example shown below, you will be subscribing to an Innovator plan. A pop-up window will appear, and you will need to fill in your payment details.
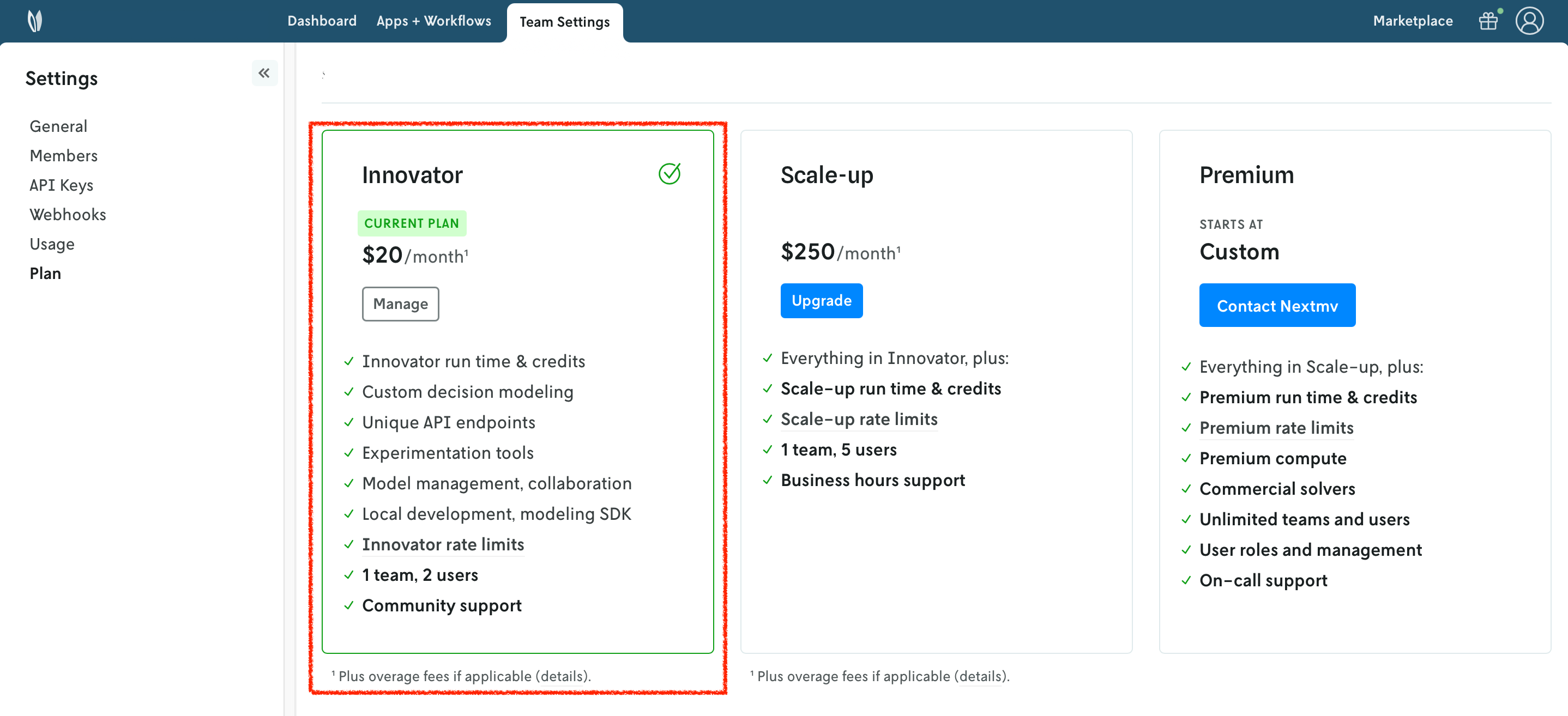
Once your account has been upgraded, you will see an active plan in your account.
11. Push your Nextmv application
So far, your application has run locally. You are going to push your app to Nextmv Cloud. Once an application has been pushed, you can run it remotely, perform testing, experimentation, and much more. Pushing is the equivalent of deploying an application, this is, taking the executable code and sending it to Nextmv Cloud.
Create another script, which you can name app5.py, or use another cell in the Jupyter notebook. Copy and paste the following code into it, making sure you use the correct dirpath for the Manifest.from_yaml method and app_dir for the push method:
This script will push the executable code to the application.
After you run the script, or notebook cell, you should see an output similar to this one, where it shows the app being bundled and pushed to Nextmv Cloud.
Refreshing the overview of the application in the Nextmv Console should show the following:
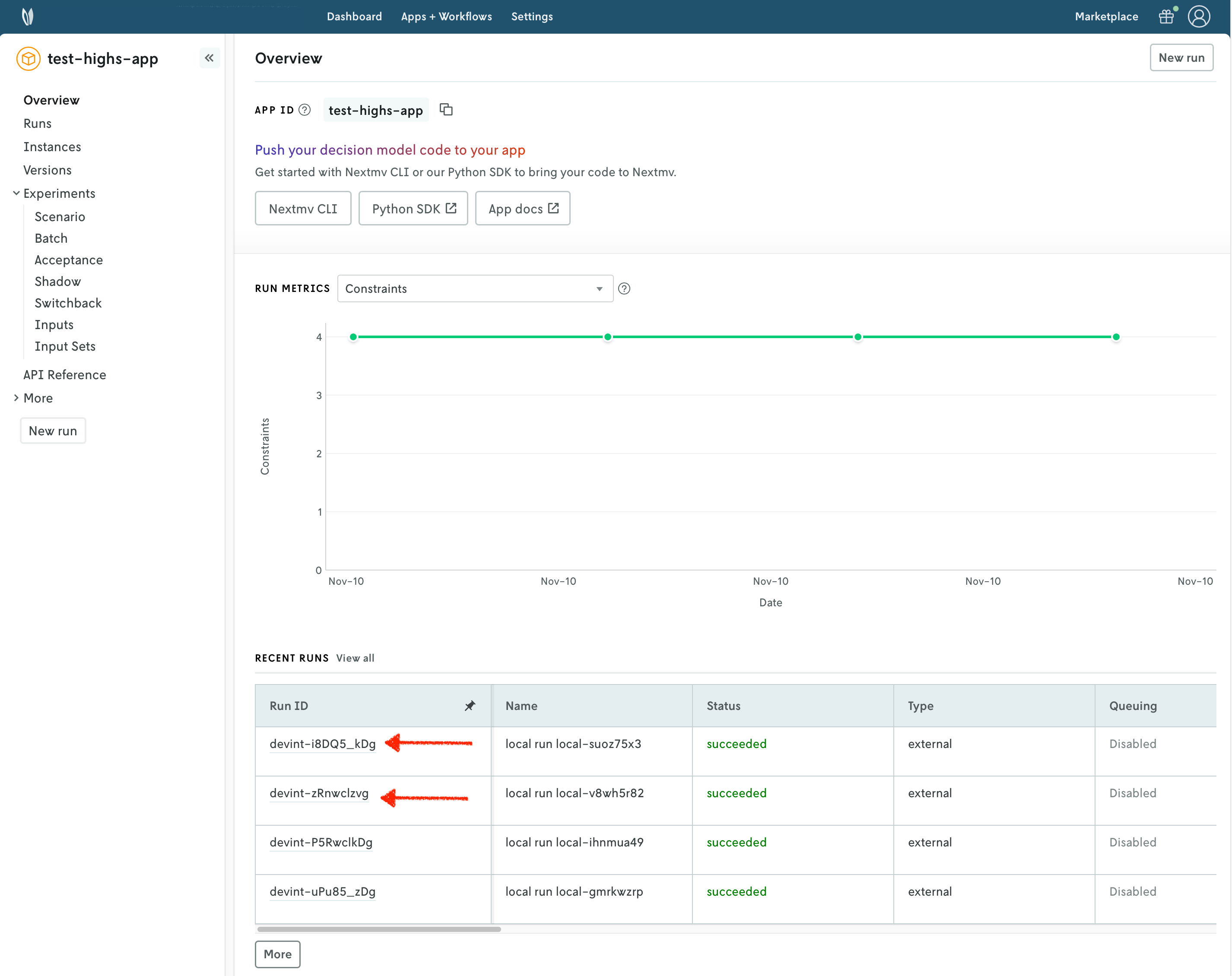
- There is now a pushed executable.
- There is an auto-created
latestinstance, assigned to the executable.
An instance is like the endpoint of the application.
12. Run the Nextmv application remotely
To run the Nextmv application remotely, you have several options. For this tutorial, we will be using the Nextmv Console and the cloud package of the Python SDK.
In the Nextmv Console, in the app overview page:
- Press the
New runbutton. - Drop the data files that you want to use. You will get a preview of the data.
- For Pyomo, use the
problem.jsonfile. - For HiGHS, use both the
nodes.jsonandedges.csvfiles.
- For Pyomo, use the
- Configure your run according to the options that are set in the
app.yamlmanifest.- For Pyomo, you can configure the
durationandsolver. - For HiGHS, you can configure the
duration.
- For Pyomo, you can configure the
- Start the run.

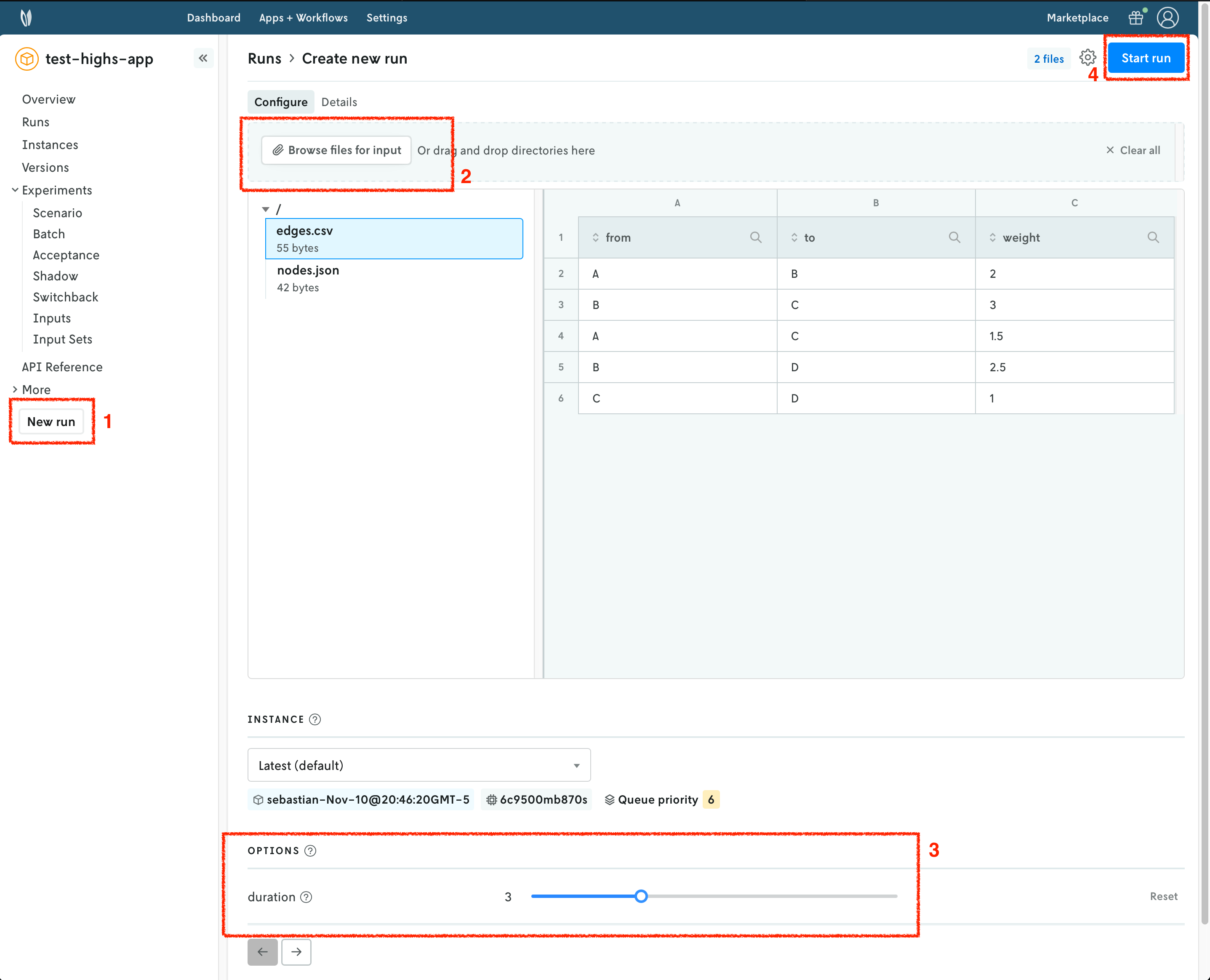
Navigate around to visualize the results of the run. This should look, and feel, like the external (local) run you tracked in a previous step. In this case, the run was executed on Nextmv Cloud.
Alternatively, you can run your Nextmv application using the Python SDK. Create another script, which you can name app6.py, or use another cell in the Jupyter notebook. Copy and paste the following code into it:
This script will start a new run on Nextmv Cloud, wait for it to complete, and print the results. After you run the script, or notebook cell, you should see an output similar to this one:
13. Perform a scenario test
We are going to take full advantage of the Nextmv Platform by creating a scenario test. Scenario tests are generally used as an exploratory test to understand the impacts to business metrics (or KPIs) on situations such as:
- Updating a model with a new feature, such as an additional constraint.
- Comparing how the same model performs in different conditions, such as low demand vs. high demand.
- Doing a sensitivity analysis to understand how the model behaves when changing a parameter.
Start by creating an input set. As the name suggests, it is a set of inputs, and it serves as a base so that we can perform runs varying one or more configurations (options). To create an input set, you have several options, like using the cloud package of the Python SDK. For this tutorial, we will be using the Nextmv Console. You may follow these steps for both examples.
- Navigate to the
Input setssection. - Set a name for your input set.
- Use the
Instance + date rangecreation type given that we already have a few runs on thelatestinstance. - Create the input set.

Another option for creating the input set is using the Python SDK. Create another script, which you can name app7.py, or use another cell in the Jupyter notebook. Copy and paste the following code into it:
This script will create a new input set. After you run the script, or notebook cell, you should see an output similar to this one:
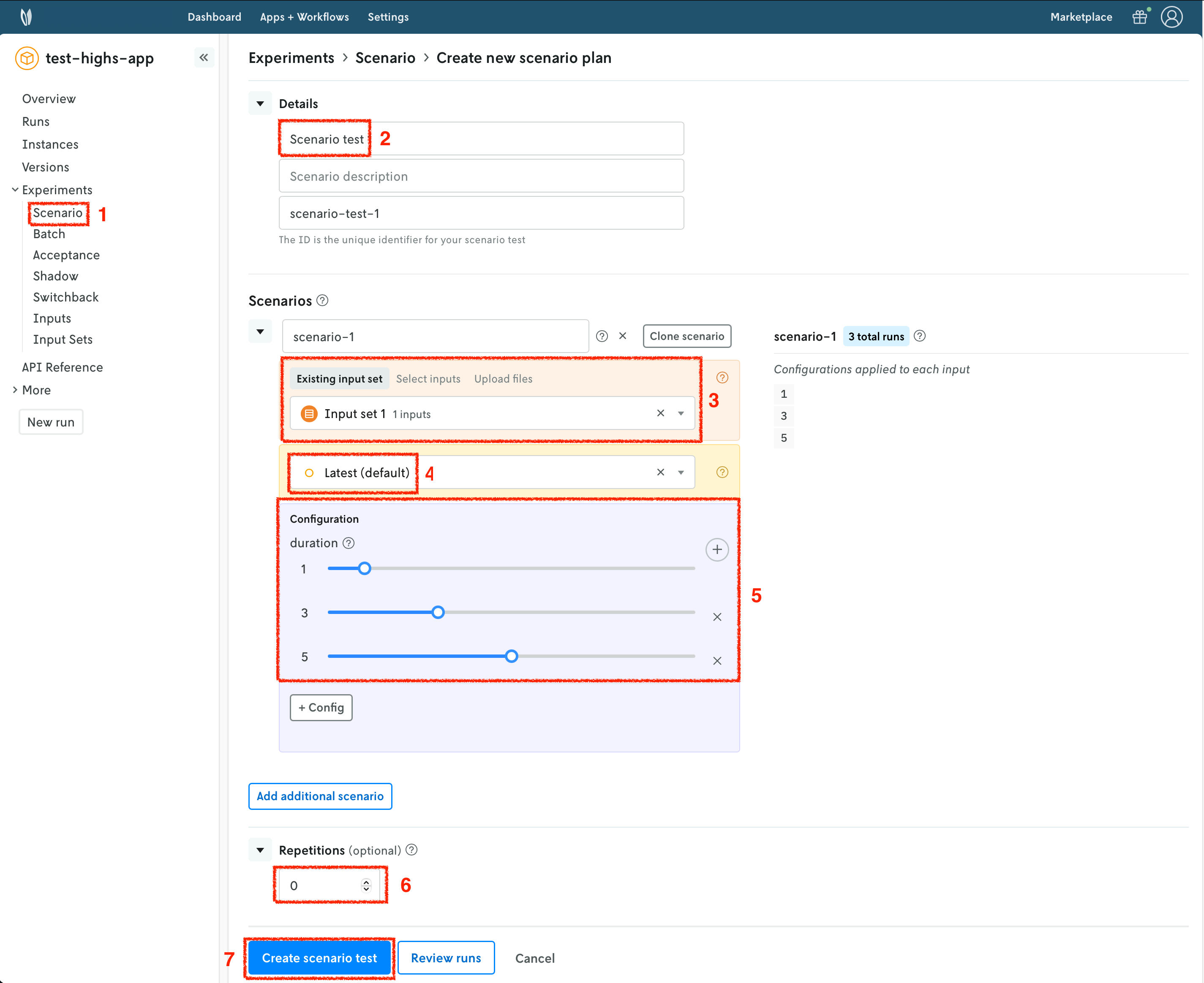
Once your input set has been created, we are going to create a scenario test. Similarly to runs, and input sets, you have several options to achieve this. We will continue to use the Nextmv Console and the cloud package of the Python SDK in this tutorial. You may follow these steps for both examples.
- Navigate to the
Scenariosection. - Set a name for your scenario test.
- Select the input set you just created in the previous step.
- Select the
latestinstance. - Create configuration combinations, which will be factored in to create the scenarios.
- For Pyomo, we are setting
durationto be 1, 3, and 5 seconds; and forsolverwe are comparing the three supported solvers:glpk,scipandcbc. - For HiGHS, we are setting
durationto be 1, 3, and 5 seconds.
- For Pyomo, we are setting
- Optionally, you may configure repetitions. These are useful when the results are not deterministic.
- Create the scenario test. Review and confirm the number of scenarios that will be created.

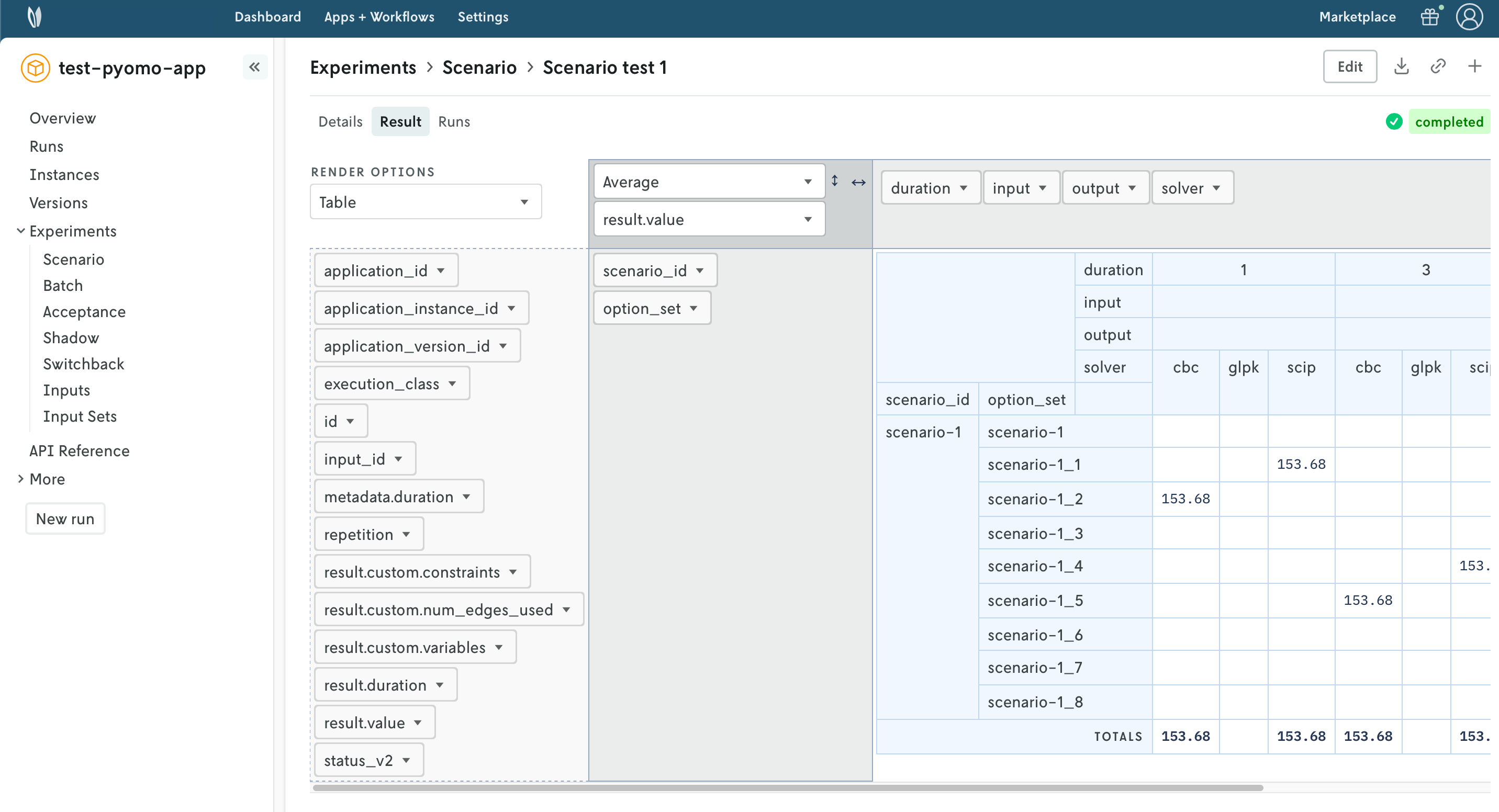
Once all the runs in the scenario test are completed, you can visualize the result of the test. A pivot table is provided to create useful comparisons of your metrics (statistics) across the scenario test runs.
As an alternative, you may create the scenario test using the Python SDK. Create another script, which you can name app8.py, or use another cell in the Jupyter notebook. Copy and paste the following code into it:
This script will create a new scenario test. After you run the script, or notebook cell, you should see an output similar to this one:
🎉🎉🎉 Congratulations, you have finished this tutorial!
Full tutorial code
You can find the consolidated code examples used in this tutorial in the tutorials GitHub repository. The connect-your-model-python dir contains all the code that was shown in this tutorial.
For each of the examples, you will find two directories:
original: the original example without any modifications.nextmv-ified: the example converted into a Nextmv application.
Go into each directory for instructions about running the decision model.