


Every year, as we’re planning for what’s next, I like to reflect on the journey so far. In 2019, we heard 87% of data science projects never make it into production. In 2025, we heard 95% of AI projects fail. While there’s a lot to unpack in these narratives, one thing is clear: Success for optimization and decision science projects is not solely defined by what model you build or solver you select, but by how you build and manage them.
You can design the most perfect decision algorithm, but if stakeholders can’t trust it, if it’s stuck in a never-ending engineering queue, if it isn’t testable, if its runs aren’t repeatable, if it’s hard to monitor and manage, then it will fail.
Do any of these sound familiar?
- “My metrics don’t match yours. What input did you use?”
- “Can you email me your run logs?”
- “I think I overwrote my results again…experiment-5-final-final(1).json was it?”
- “Do you have time to expose these new solver options for testing?”
- “Well…it worked on my machine.”
Why is it that algorithms designed to deliver literally millions of dollars in ROI are so inefficiently developed and often dependent upon fantastically fragile production workflows? It doesn’t have to be this way, especially in 2026, and I’ll show you why.
The journey more recently…
I hosted several sessions late last year on various aspects of decision systems as part of our DecisionFest. One standout conversation was on agility in operations research and decision science with practitioners from Grubhub, IKEA, and Aimpoint Digital. We explored what it takes to get decision model value into the hands of stakeholders quickly. Because we’re all striving for the moment one panelist described:
Nothing feels better than someone asking a really critical question and then saying, "Well, let me just test this in the optimizer, run it again, and look at that scenario."
Your alternative is: Let me think about that. I'll run some analysis. Let's schedule a meeting. When do all of our schedules align? Let's get back in a week…and we'll have your answer. By then, you'll have lost momentum. You'll have to remind people where you started and where you are.
Instead…you're progressing the model or adding a new feature or putting in a new automated scenario to answer that question proactively. Because end users want that responsiveness and developers don't want to have to build that every time. That pre-built structure is really important.
If you have a good structure for logging your steps, capturing your results, tracking versions, and partitioning environments, your path to stakeholder trust and production becomes more straightforward and reliable. Let’s take a spin through some relatively recent developments that speak to this.
Expanding the ecosystem: FICO, NVIDIA, Databricks, workflows
One of the hardest things about the decision intelligence space is making all of the technologies you want (or have) to use work together seamlessly. For example, you may want to pull data from a particular data source into a decision model written in Python and link it with a simulation written in Java. In order to activate decisions within a business, you have to have a model, infrastructure, and an API. Plugging decision models into software architectures is where projects flounder and fail.
Nextmv provides the infrastructure, workflows, and standards to abstract away the complexity that goes along with that. It works really hard to let users plug and play with different execution, models, solvers, simulations, heuristics, rules engines, etc. and it all just works the same way.
We’ve invested in expanding the ecosystem of technologies that work with Nextmv to include the FICO Xpress solver, NVIDIA cuOpt solver, NVIDIA GPU compute, Databricks execution, and a flexible secrets framework that allows you to connect to any other platform..
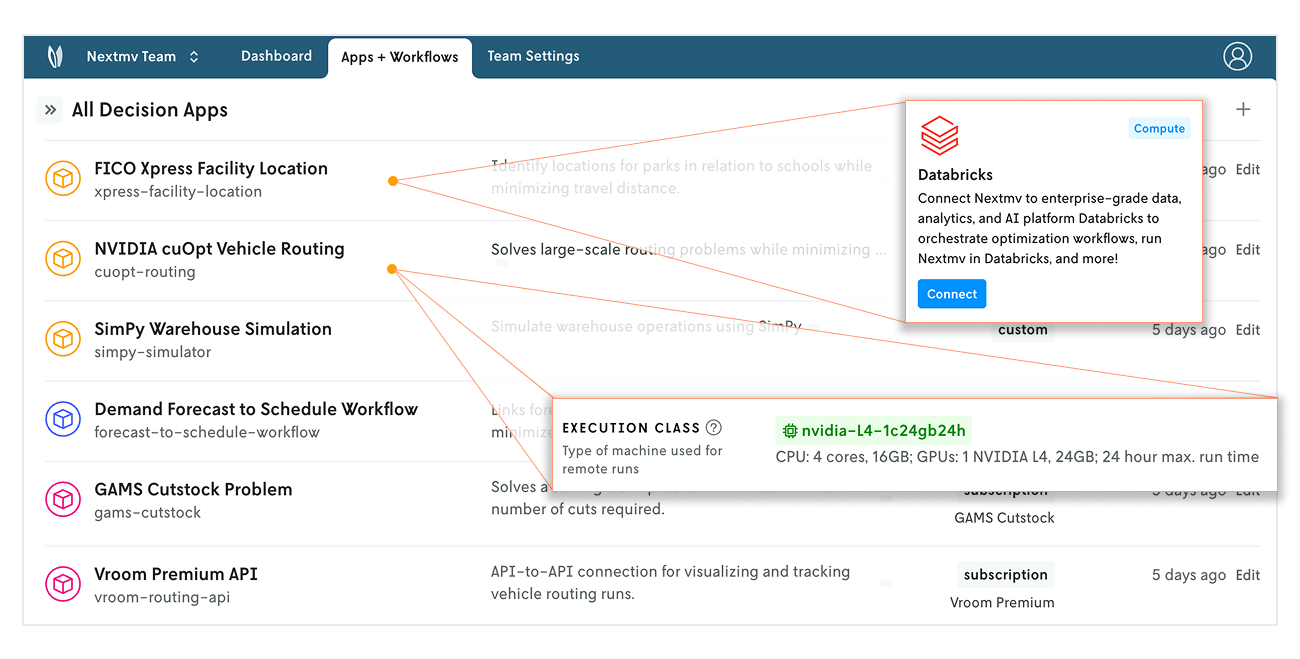
The easier it is to connect the technologies you want to use or experiment with into your optimization workflows, the better chance practitioners have of success. Just plug and play.
Manage models end to end: Versions, environments, config
Applying optimization to real-world operations can feel like a patchwork of configurations that take real time and resources to manage and maintain. Vehicle routing works one way in New York City and another way in Denver. Schedules are created in the same way in San Francisco and Toronto, but not in Amsterdam or Sydney. A development environment may be configured differently than a staging environment, which mirrors the high-powered production environment. And there’s a just-in-case fallback option always running in the shadows should operations go sideways.
Nextmv has made it easier than ever before to track model versions (Version 1 has one objective function while Version 2 is multi-objective), create model instances (by geographic region or development environment) with different configurations (constraint A is true here, but false there), set and modify compute (go from from serverless to GPU in a click), and define run queues (production runs take priority over experimentation runs).
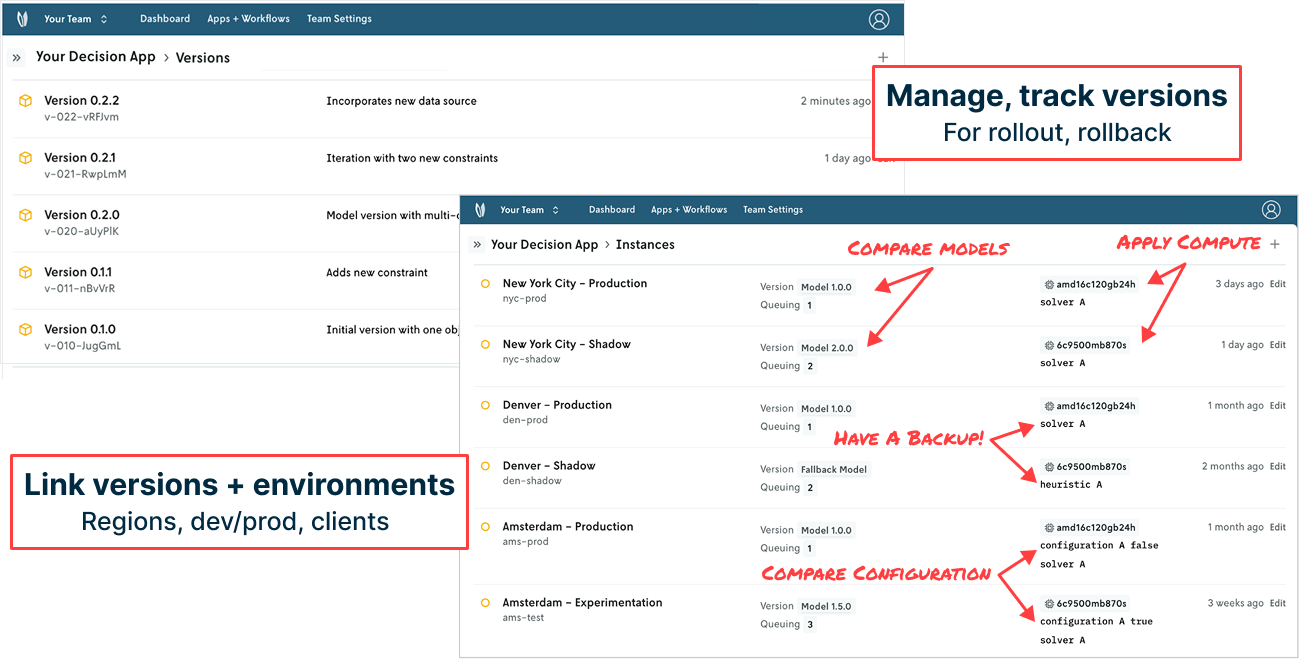
With connection points to git-based tools, systematically shipping, managing, and exposing model versions to the right end user in the right way is more seamless than ever. And it doesn’t require any engineering build-out, effort, or maintenance. It’s all just there and works.
Sliders and dropdowns and toggles, oh my!
UI components are useful for structured interactions with decision models, especially with operators, analysts, and business users. They provide guardrails to help collaborators interface with models more quickly and systematically.
Nextmv makes it so modelers can use a simple app config to expose these elements for model exploration and prototyping across teammates. Product managers and business users can explore and compare what-if scenarios with different model configurations. Modelers can prototype and evaluate new solvers or model formulations that are in earlier development.
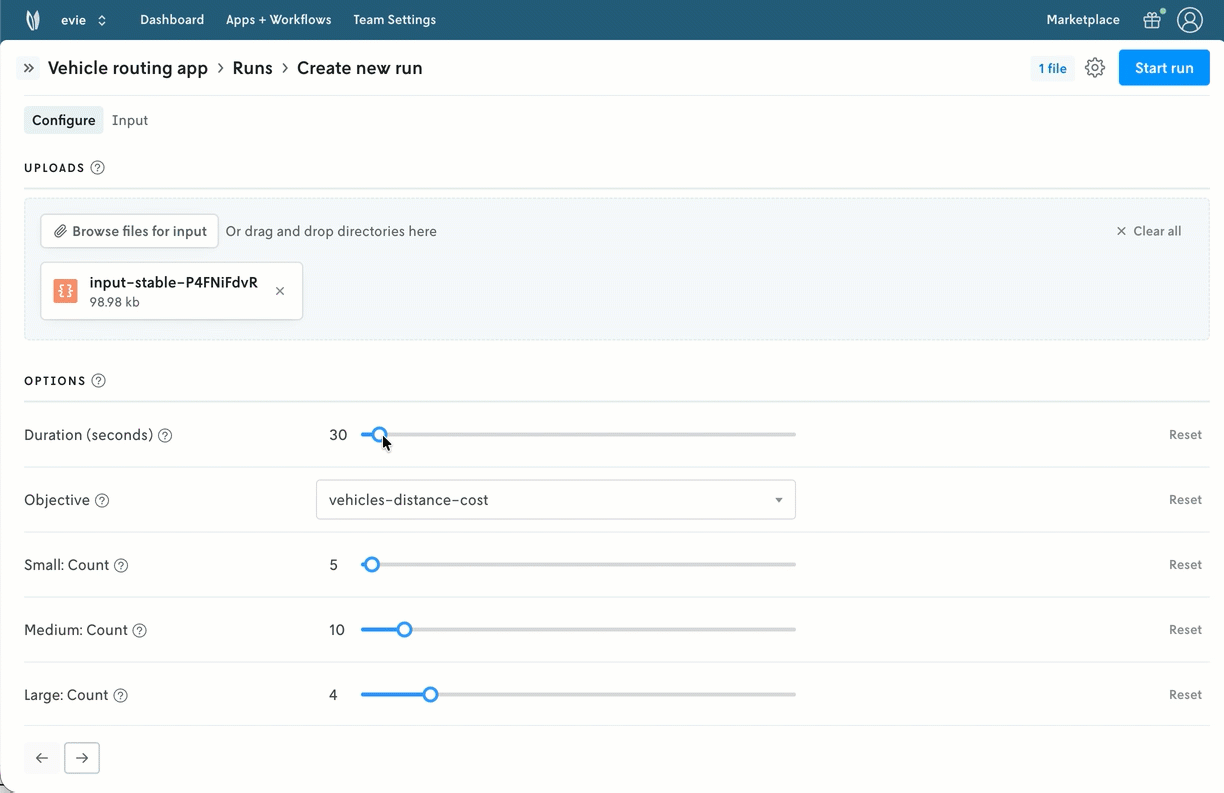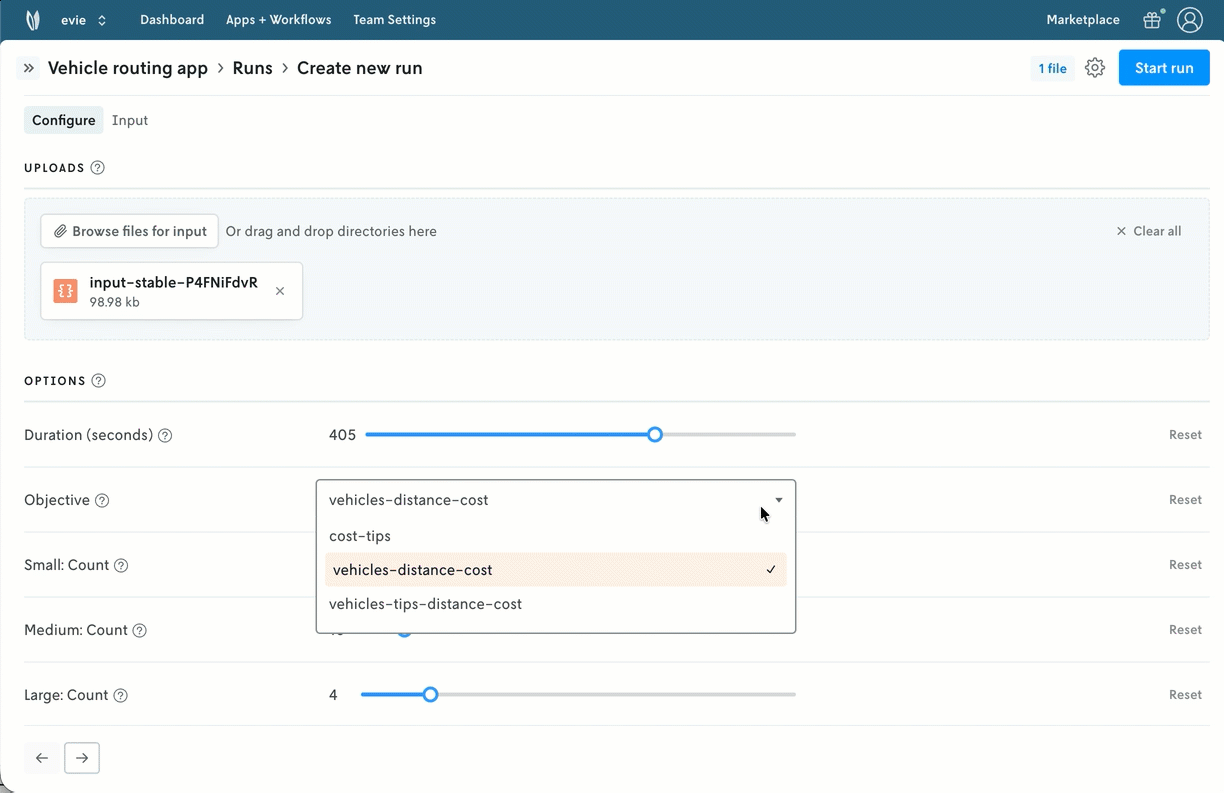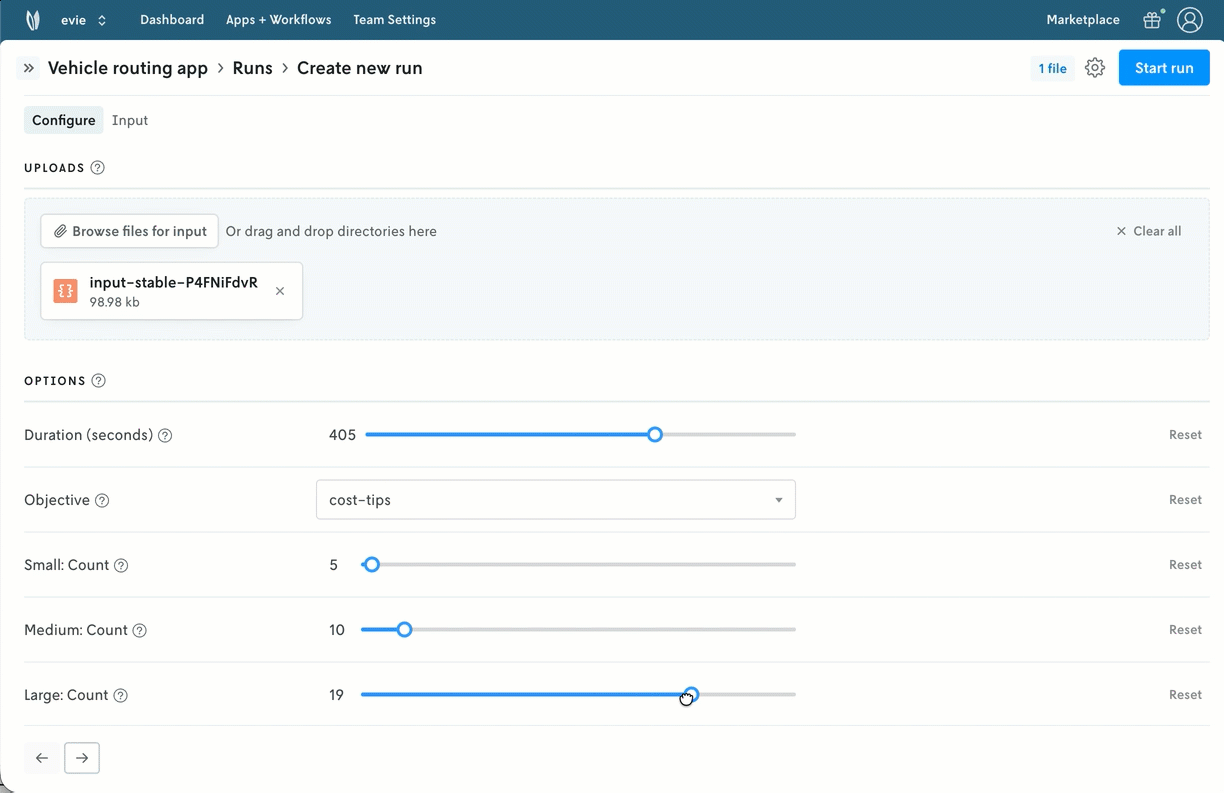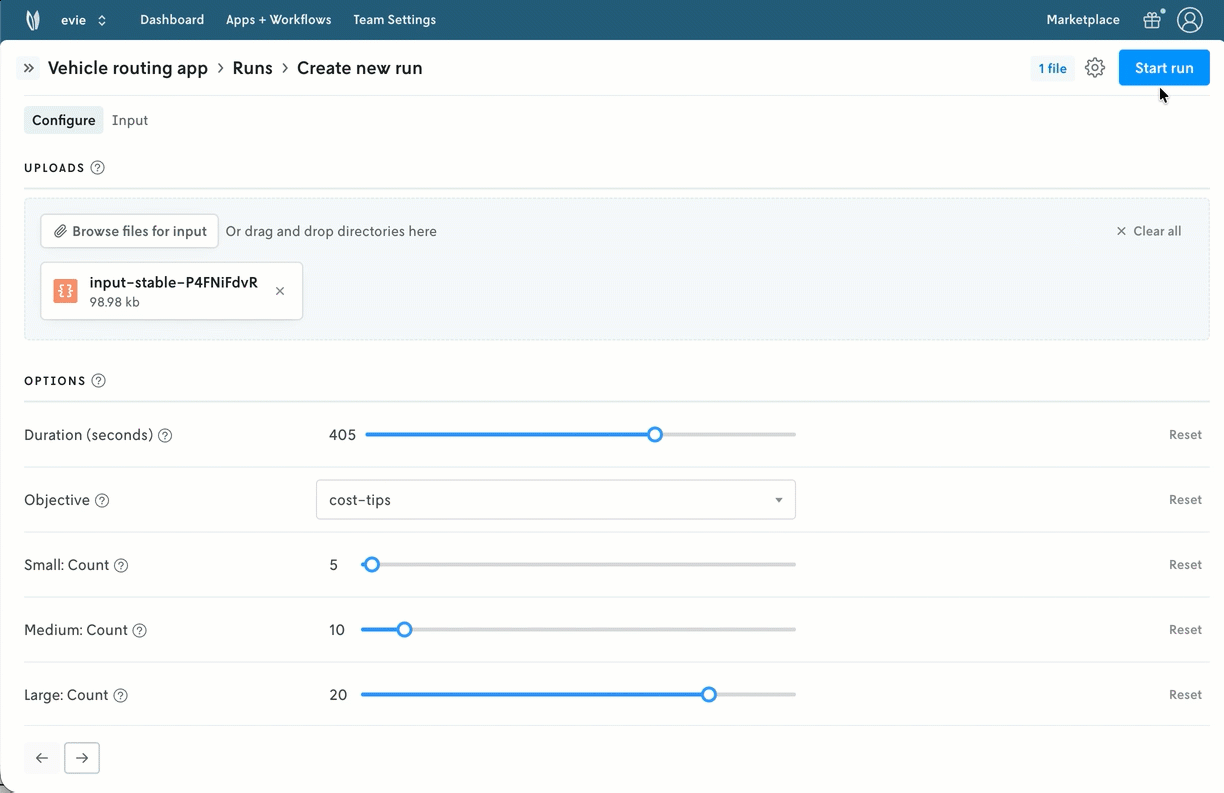
Ultimately, you can also focus your operators and end users on the configurations that are relevant to them.
Download, clone, tweak, compare, and pick the best one
How long does it take you to recreate an input file or the options/configuration for an optimization run? We hear tales of practitioners spending hours, days, weeks diving in and out of multiple data stores and gluing data points together to reproduce a run. (Note: That excludes the oh-so-fun meetings that likely go along with this task.)
Nextmv is a system of record for optimization models, which makes it easy to know who ran what, when, and with what input and output — and then clone, repeat, compare, and even pick the best solution for multiple runs.
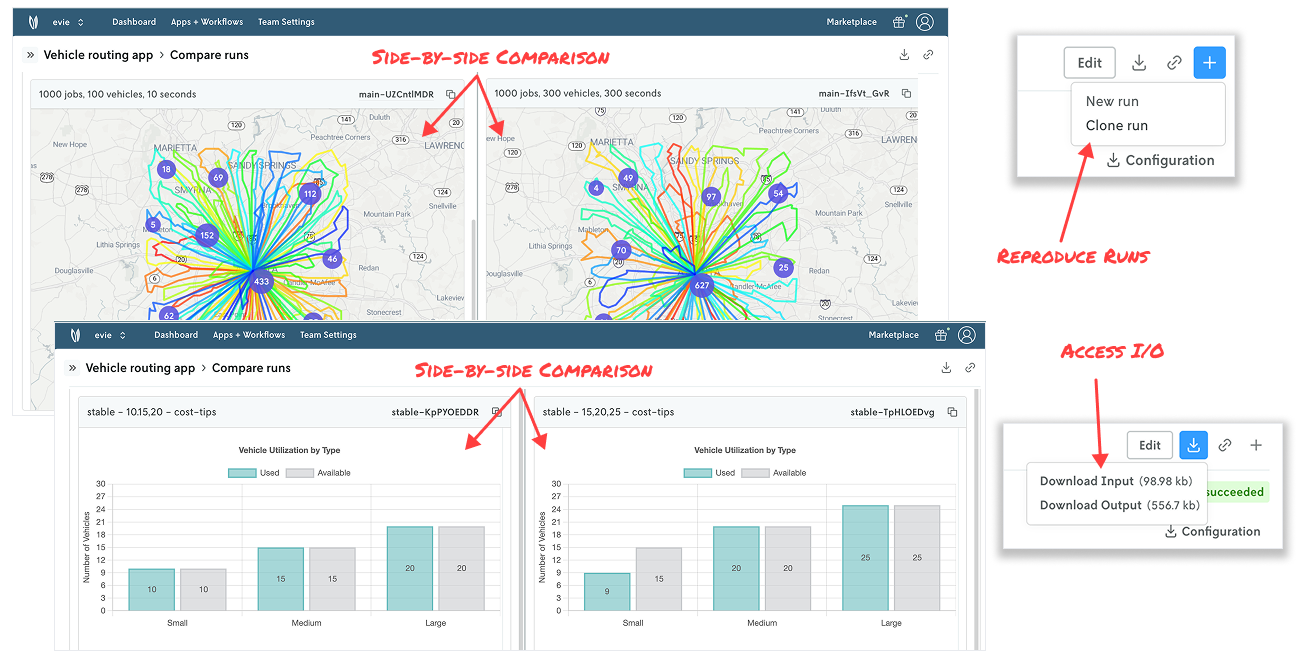
Referencing a run input or output is a tab in Nextmv that’s a click away. Want to inspect or run it locally? Great, just click download. Reproducing a run: Click “clone run” and re-run. Want to compare one run to another? Select the two runs, click “compare”, and review them side by side. Want to level up your game and define criteria that make a run the “best” among several runs? Leverage ensemble runs.
It doesn’t get much easier than this.
Quickly adding DecisionOps to a new or existing model
For adoption of any technology, there is a valid worry about onboarding effort. Will you have to redefine variables? Or rewrite your model entirely? We understand these concerns. We’ve lived them.
Wiring up a model (new or existing) to Nextmv is as simple as adding a few lines of code. From there you can immediately improve your optimization workflows and outcomes. That’s not an exaggeration. You now have the structure to systematically track your model runs, metadata, experiments, visualizations, and outcomes — be that locally with an open source DecisionOps framework or remotely for scaled-up workloads.
Adding DecisionOps to your projects used to be costly, intensive, and hard. It’s not anymore.
The journey ahead…
The AI narrative still dominates the broader technology space. Within decision intelligence, many companies are developing AI tools to streamline model building and solver set up. While this lowers the barrier to entry for optimization adoption, this flavor of GenAI for OR doesn’t solve the application challenge.
Many of the recent OR conversations have been around building end user trust and turning what’s perceived as black-box optimization into clear-box decision-making. This entails answering questions such as:
- How have results drifted over the last quarter?
- Which runs were executed with a given order number?
- When did runs go beyond our set threshold?
- Which runs have neared compute limits over the last month?
- What are key takeaways from the most recent batch of scenario tests?
Answering these questions relies on having a system of record to reference and learn from: LLM or otherwise. And you can only get a system of record if the right infrastructure is set up to systematically log all production runs, experiments, the metrics and KPIs, visualizations, results, metadata, solver logs, input and output, and so on. That is exactly what Nextmv is designed to do.
We are investing in these types of AI initiatives to complement the work being done to simplify the modeling process. At the same time, our focus ahead is not all-consumed by AI. We are invested in better evangelizing model management and CI/CD best practices, improving DecisionOps workflows, and providing greater optionality in our Nextmv ecosystem for optimization, compute, visualization, ML, and more.
Food for thought
Logistics innovators such as DoorDash and Stitch Fix invested early in building and maintaining tools to build and maintain decision models. In most cases, these types of in-house initiatives require significant investments in up-front and recurring costs on the order of millions. But it’s not 2015 anymore.
In the same way you use GitHub for developing code or Google Docs for writing reports in order to avoid sorting through and reconciling attachments, changes, and updates in email threads 60+ replies long, you can pick up Nextmv, a ready-to-go DecisionOps solution, to streamline your decision model lifecycle.
As Swiggy’s VP of Data Science recently said in an interview, “Machine learning has clear pipelines for data, training, and deployment. Decision systems have remained very bespoke and ad hoc.” That should no longer be the case. Just as any team developing software employs DevOps, or any team developing ML models has MLOps, every decision scientist should have DecisionOps.
Some food for thought to leave you with: As you think about your road ahead, do you want to spend time building and maintaining tools to build models or do you want to instead spend time building and iterating on models that deliver value and innovation back to the business?





